Improving Lunar Topography with Deep Learning Schrödinger Bridges
Erwan MazaricoAuthors: Matthew Repasky, Erwan Mazarico, Michael K. Barker, Stefano Bertone, Terence J. Sabaka, Yao Xie
Overview
We present a machine-learning approach for improving the resolution of lunar Digital Elevation Models (DEMs) by a factor of 16×, from a 320 m/pix a priori DEM to a 20 m/pix reconstruction, using sets of high-resolution optical images as physical context. The method is based on an image-to-image Schrödinger Bridge (SB) generative model parameterized with a Vision Transformer (ViT) backbone, operating in the latent space of a topography Variational Auto-Encoder (VAE). Unlike standard diffusion super-resolution, the SB initializes its generative process directly from the low-resolution input rather than pure noise, which we find to be well suited to topography reconstruction. The model is trained on 96×96-pixel (1.92×1.92 km) patches extracted from the LOLA polar DEMs poleward of 80° latitude, paired with ray-traced renderings of those patches under realistic lunar illumination conditions that emulate LROC NAC imagery, including missing-data patterns. Because the SB is stochastic, multiple independent reconstructions (“clones”) can be drawn per patch to produce mean topography and pixel-wise uncertainty maps. A tiling-and-mosaicing scheme, inspired by the Ames Stereo Pipeline sfs and dem_mosaic tools, enables application to arbitrarily large regions. On a 9,171-patch held-out test set at 16× SR with 75 realistically illuminated images per patch, the fully fine-tuned model achieves an RMS elevation error of 5-6 m (~25-30% of a pixel width) and mean slope errors below 2°, with no significant degradation across latitude or number of input images.We emphasize that this work is a methodological demonstration. The authors note that the approach should not yet be directly compared to mature classical SfS pipelines; its principal advantages are post-training inference speed and uncertainty, whereas classical SfS is not bounded to trained resolutions.
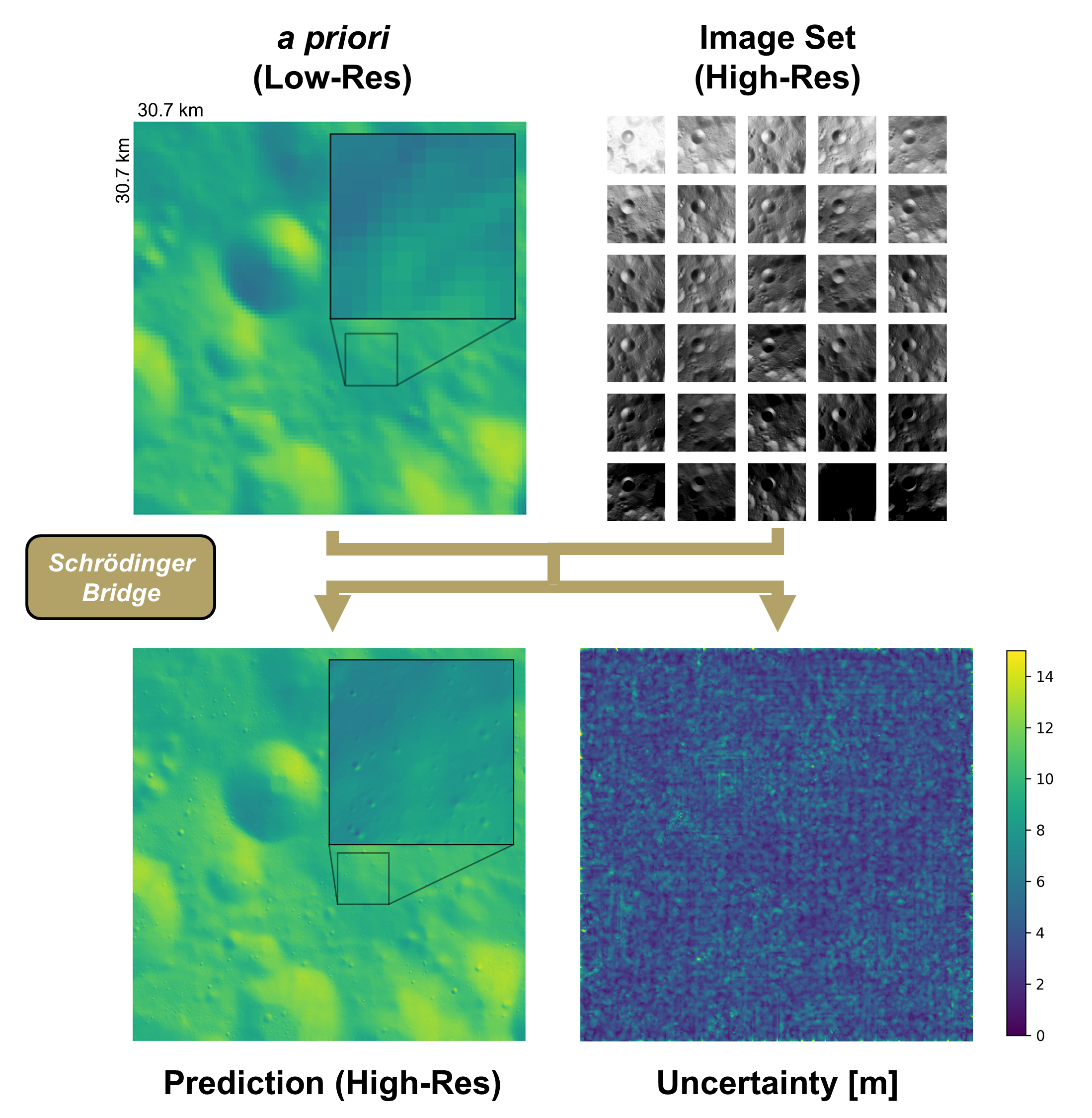 Figure 1. Schematic of the Schrödinger-Bridge super-resolution workflow.
A low-resolution a priori DEM and a set of high-resolution images are combined by
the SB model, which produces multiple high-resolution reconstructions. Pixel-wise
statistics across these samples yield a mean DEM and an uncertainty map.
Figure 1. Schematic of the Schrödinger-Bridge super-resolution workflow.
A low-resolution a priori DEM and a set of high-resolution images are combined by
the SB model, which produces multiple high-resolution reconstructions. Pixel-wise
statistics across these samples yield a mean DEM and an uncertainty map.
Background and Context
LOLA-based polar DEMs are the geodetic reference for lunar topography, but their effective resolution is limited by altimetric sampling density, and many regions require interpolation between tracks. LROC NAC images cover the same terrain at 0.5-3 m/pix, carrying shading information that constrains slopes through photoclinometry / Shape-from-Shading (SfS). Classical SfS pipelines (e.g., the Ames Stereo Pipeline) exploit this information through iterative physical inversion. This work explores a complementary, data-driven route: a conditional generative model that learns to map low-resolution DEMs to higher-resolution DEMs when guided by illumination-consistent images. It builds on recent diffusion-based super-resolution methods and the image-to-image Schrödinger Bridge formulation, adapting them to the specific geometry and noise properties of lunar polar topography. Once trained, inference is fast and naturally produces uncertainties, which is difficult to obtain from classical SfS.Data and Methods
Training data. 91,708 LOLA DEM patches (96×96 pixels, 20 m/pix, 1.92×1.92 km) from both polar regions > 80° latitude, filtered to retain only patches with sufficient non-interpolated altimetry; split 80/10/10 into train/validation/test. Each patch is rendered under 360 fixed illumination directions on a ring pattern with a ray-tracing planetary shape-model renderer, then sub-selected to realistic sun arcs defined by each patch's assumed longitude/latitude. Missing-data patterns emulating NAC swath geometry are applied during fine-tuning.Model. The SB model operates in the latent space of a pre-trained VAE. This approach enables efficient generation of high-resolution DEMs, as the iterative generative process is conducted in a space which is low-dimensional and captures salient features of the DEM. Details are as follows:
- Variational Auto-Encoder: A topography VAE (~21 M parameters) compresses 96×96 DEM patches to a 4×12×12 latent tensor, trained with a reconstruction + adversarial + KL objective (following Rombach et al. 2022).
- Schrödinger Bridge: A latent-space image-to-image Schrödinger Bridge is parameterized by a ViT that receives three conditional embeddings per time step: the time index, an embedding of the a priori low-resolution DEM, and a set-based embedding of the available images.
- Training: Training proceeds in three stages: a main phase on Fibonacci-lattice illumination (~260k iterations), then fine-tuning on realistic illumination (~5.3k iterations), then fine-tuning with missing-data patterns (~2.8k iterations).
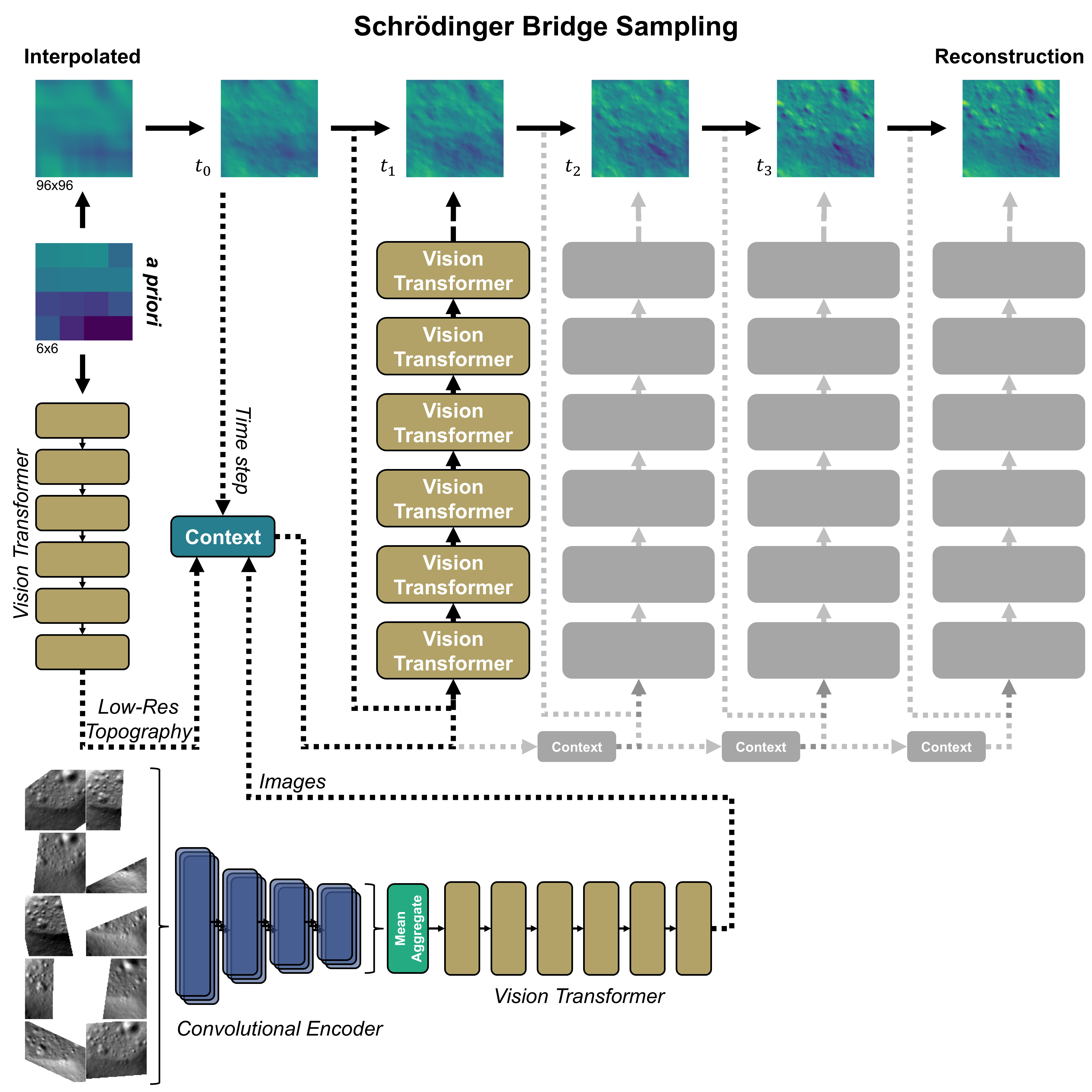 Figure 2. Flow chart of the SB generative process. The main ViT takes the partially-generated patch from
the previous time step as input to yield the next-time-step patch. Three pieces of conditional information are
incorporated: the encoded generative process time step, an embedding of the a priori topography via another
ViT, and an embedding of the set of images via a set convolutional encoder and a ViT. This conditional information
is processed by the ViT in each time step.
Figure 2. Flow chart of the SB generative process. The main ViT takes the partially-generated patch from
the previous time step as input to yield the next-time-step patch. Three pieces of conditional information are
incorporated: the encoded generative process time step, an embedding of the a priori topography via another
ViT, and an embedding of the set of images via a set convolutional encoder and a ViT. This conditional information
is processed by the ViT in each time step.
Inference and mosaicing. Multiple stochastic samples per patch yield a mean DEM and an uncertainty (standard deviation) map. For regions larger than a single patch, the SB is run as a moving window with user-specified stride (e.g., 960 m / 48-pixel stride for 50% overlap), with per-pixel blending of overlapping clones. Demonstrations include rendered large-area scenes at assumed latitudes of 0° E, 40°0-60° N with 1,500 input images including NAC-like missing data, plus a preliminary test on downsampled real NAC imagery.
 Figure 3. A region within the Faustini Rim A candidate landing region for
the upcoming Artemis missions is reconstructed given 145 real NAC images.
Figure 3. A region within the Faustini Rim A candidate landing region for
the upcoming Artemis missions is reconstructed given 145 real NAC images.
Product Availability
This page describes a super-resolution method and demonstration. Trained-model artifacts, code, and any associated rendered-data snapshots referenced by the paper are hosted externally on Zenodo, doi:10.5281/zenodo.14170309.Product Usage Policy
Please cite the following reference when using any of the products described above:Repasky, M., Mazarico, E., Barker, M. K., Bertone, S., Sabaka, T. J., and Xie, Y., 2026, Improving Lunar Topography with Deep Learning Schrödinger Bridges, The Planetary Science Journal.
Repasky, M., Mazarico, E., Barker, M. K., Bertone, S., Sabaka, T. J., and Xie, Y., 2024, Archived codebase for "Improving Lunar Topography with Deep Learning Schrödinger Bridges", Zenodo, doi:10.5281/zenodo.14170309.
References
Repasky, M., Mazarico, E., Barker, M. K., Bertone, S., Sabaka, T. J., and Xie, Y., 2026, Improving Lunar Topography with Deep Learning Schrödinger Bridges, The Planetary Science Journal.Repasky, M., Mazarico, E., Barker, M. K., Bertone, S., Sabaka, T. J., and Xie, Y., 2024, Archived codebase for "Improving Lunar Topography with Deep Learning Schrödinger Bridges", Zenodo, doi:10.5281/zenodo.14170309.
Liu, G.-H., Vahdat, A., Huang, D.-A., et al., 2023, ICML (Image-to-Image Schrödinger Bridge).
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B., 2022, CVPR (Latent Diffusion / VAE backbone).
Bertone, S., 2024, Zenodo, doi:10.5281/zenodo.14018762 (ray-tracing illumination software).